BI-text-mining
An academic project that aims to extract and process text from a large amount of articles scrapped from many Moroccan news Websites.
This project is divided into 5 parts, each part is in an independent directory:
- [Part 1]: Scraping
- [Part 2]: Text_processing
- [Part 3]: Automating
- [Part 4]: Reporting
- [Part 5]: Mining
Further Details
1. Scraping :
Scrapping articles (Title, publiction date, Image, Link, Full text…)from Moroccan news websites(BeatifulSoup and requests).
Ressources :
Data was retrieved from the following websites:
Data structure :
We scrapped the Economy subcategory pages for each news website. for each article we got its :
titlepublication dateimagelinkfull text.
2. Text_processing :
Apply some text mining methods and algorithms(TF,IDF, NMF, TOPIC MODELING).
-
Texts are pre-treated and cleaned using the basic text processing techniques such as :
removing stop wordslemmatizationstemmingtokenizationremoving punctuationremoving numbersandremoving special characters.
-
Then we’ve applied some text mining algorithms such as :
TF-IDFNMFTopic Modeling.
3. Automating :
Automate the process of scraping, text processing, Datawarehousing and loading Data into Postgresql Database(Airflow, Docker…). The Datapipeline architecture is as follows:

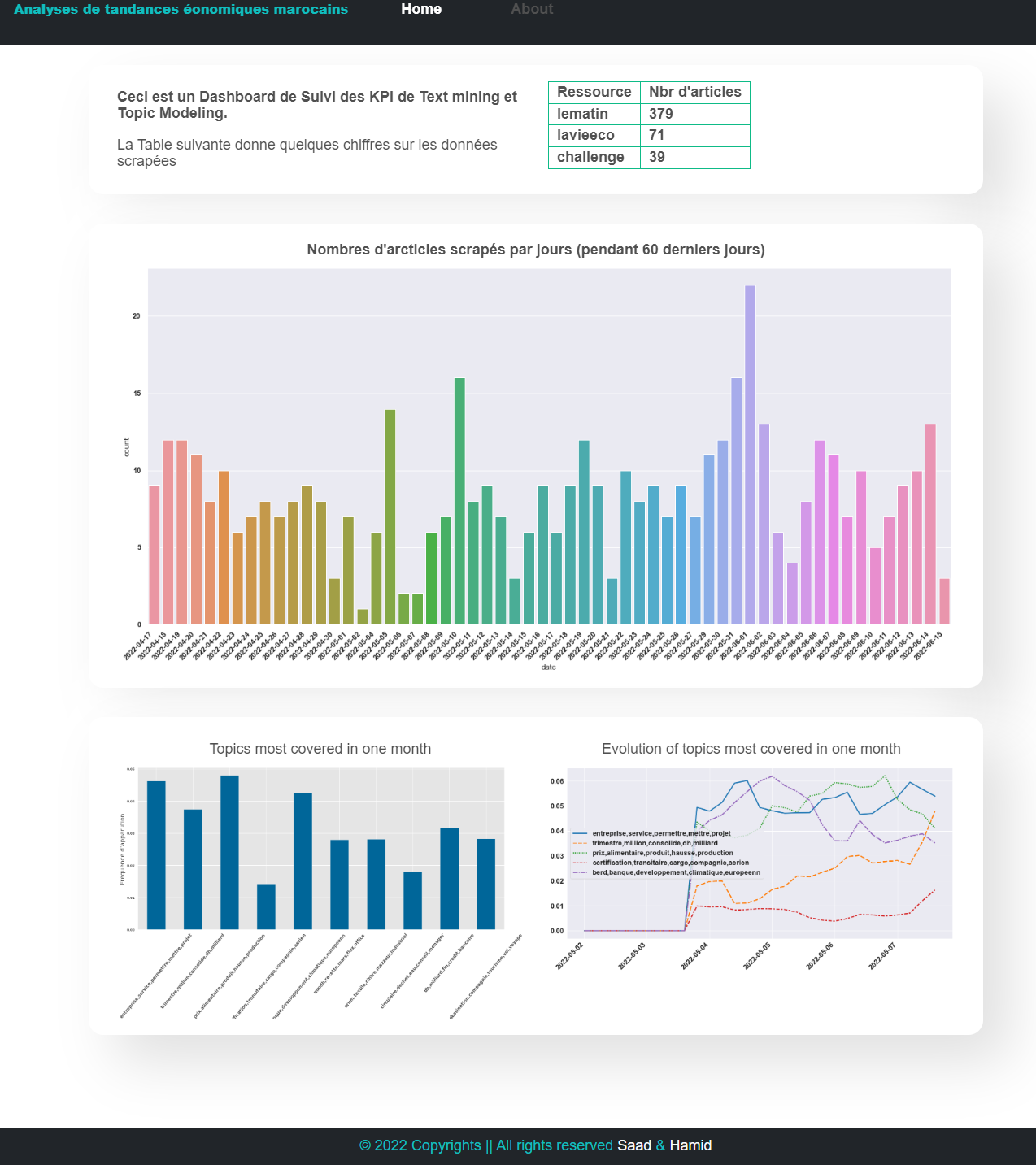
4. Reporting :
Present results and key measures in a dashboard (Web app with Flask).
Reporting results via a simple dashboard as follows:
5. Mining :
Extract association rules (R and python).
Contrubutors :